[Devlog 4] Table of Contents, S3 Migration
Nathan Luong | May 24, 2023 |5
🤔 What's new? TLDR
👉 Major Changes
-
Adding Table of Contents:
- Using the
remark-tocplugins, a table of content can be generated from the existing Markdown Heading Structure. - The table of content will link to different headings via their HTML
idattribute - The Table of Content can be generated by simply adding a heading with the title
Table of Contentsdirectly inside of the markdown blog.
- Using the
-
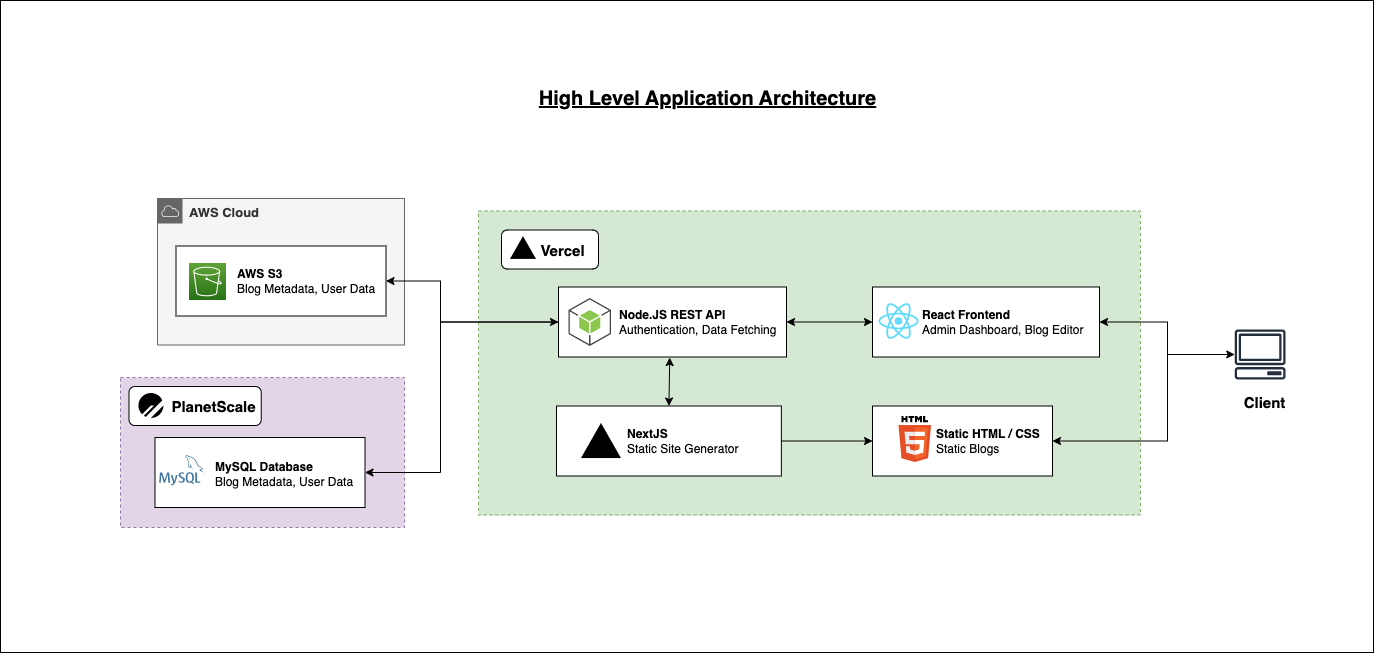
Moving blogs from the local file system onto AWS S3
- As the feature name hinted, blog markdown objects will be migrated from the server onto S3.
- Metadata such as Title, URL, Published Date, or Views will be stored inside a MySQL relational database, hosted on PlanetScale
- Additional API routes needed to be in place to handle the fetching of the blogs.
👉 Minor Changes
- UI changes for
admin/dashboard- Each card will have a custom pop-up to display customized information.
- Custom pop-ups are passed in as props, with a type of
JSX.Elementornull - Pop-ups can be closed via the icon on the right
- Blogs on
blogs/index.tsare now sorted by published date instead of the default ascending UUID - Refactoring
ReactMarkdowncomponents into one big component calledReactMarkdownWrapperOriginally, 2 identical ReactMarkdown are being used inadmin/editorandblogs/[slug]. They are now refactored into one place.
🤔 How was it implemented?
👉 Table of Content Implementation
With the help of remark-toc, the table of content is automatically generated. For example, the following input markdown will be parsed into the following output markdown:
# Alpha
## Table of contents
## Bravo
### Charlie
## Delta
# Alpha
## Table of contents
* [Bravo](#bravo)
* [Charlie](#charlie)
* [Delta](#delta)
## Bravo
### Charlie
## Delta
The output markdown will be parsed into HTML by the ReactMarkdown component as usual. However, the challenges really come when trying to style the HTML table of content.
💡 Difficulties in Styling the Table of Content
As you can already predict from the markdown above, the parsed markdown from remark-toc has no identifier (className or id) to identify the <ul></ul> elements it created.
That means the above Markdown will be parsed as:
<h1>Alpha</h1>
<h2>Table of contents</h2>
<ul>
<li className="toc-li"><a href="#bravo">Bravo</a></li>
<ul>
<li className="toc-li">
<a href="#charlie">Charlie</a>
</li>
</ul>
<li className="toc-li"><a href="#delta">Delta</a></li>
</ul>
<h2>Bravo</h2>
<h3>Charlie</h3>
<h2>Delta</h2>
This is bad news since rendering as a generic ul element with no classes associated with it will be impossible to be targeted without affecting other ul and li items that are already styled.
💡 Solution 1: Using CSS parent selector
The obvious solution would be to use the :has() CSS selector to select ul elements with li elements with class toc-li.
However, from the time I coded this feature, the CSS parent selector is not widely supported by browsers. The biggest player that does not support :has() is Firefox. Since I wanted to increase the accessibility of the site, I will skip using the CSS parent selector for now.
💡 Solution 2: Using CSS Sibling Selector
Another solution that comes to mind is to use the CSS sibling selector ~ and +.
This is an extremely effective solution since the Table of Content only appears after the Heading with the content of Table of Content anyways.
However, choosing all ul elements that are right next to an h2 element is flawed since any ul can go right after any h2 in a markdown blog structure. Therefore, a hack was implemented 🙂.
h2: (element: headingProps) => {
if (
Array.isArray(element.children) &&
typeof element.children[0] === "string" &&
element.children[0].toLowerCase() === "table of contents"
){
return (
<>
<h2 id={headingToId(element.children[0]) + " toc-heading"}>
{element.children}
</h2>
<aside></aside>
</>
);
}
},
After every table of contents heading, it will append an empty aside element. Knowing that there are no other aside elements that will be created from the parsed markdown, styling the table of content will be extremely simple. By choosing ul right after aside, all default styling of ul and li will be overwritten
.post aside + ul {
background: #282c34;
padding: 0.5rem 0.5rem;
border-radius: 1.5rem;
margin-left: 1rem;
}
.post aside + ul li {
margin: 0.5rem;
}
.post aside + ul > li {
margin: 2rem;
}
👉 AWS S3 Implementations
The migration onto AWS S3 was pretty straightforward, thanks to the simplified process that AWS has created.
Implementation:
- Create a bucket on AWS S3.
- Upload existing markdown objects onto S3 under some bucket names.
- Create an IAM user and give it the AmazonS3FullAccess policy.
- Generate AccessKey and SecretKey from AWS IAM.
- Import them into Vercel as environment variables.
- Write an API endpoint to fetch the markdown object from AWS S3.
- Replace fetching with
fs.readFilewith the API endpoint just created.